Gigantes da tecnologia como Google e Facebook têm a seu favor enormes bancos de dados, coletados de seus usuários, e em um mundo que se encaminha para a criação de inteligências artificiais, aqueles com mais dados com que alimentar essas IAs são os agentes mais fortes. Remando contra a maré, a Mozilla decidiu criar o seu próprio projeto de crowdsourcing, para fazer uma tecnologia de reconhecimento de voz. E conta, é claro, com a contribuição do público para isso.
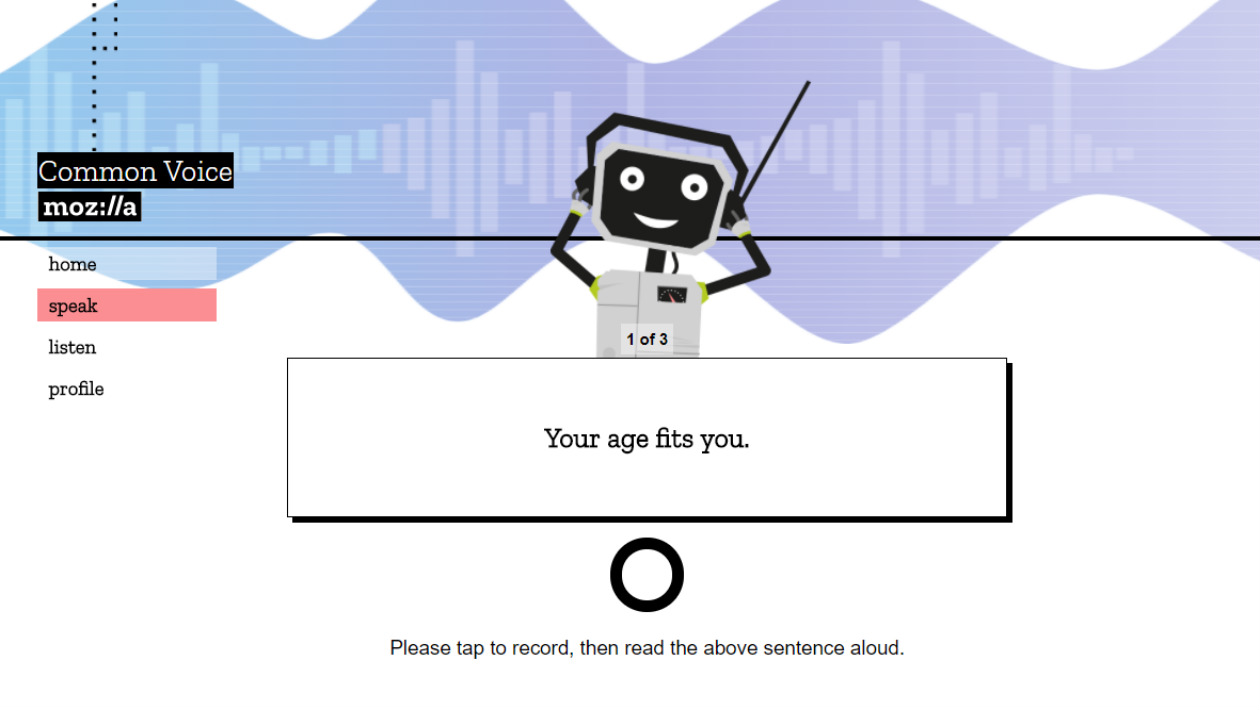
O novo projeto é uma criação da Mozilla Foundation, criadora do Firefox, e pede para que usuários contribuam enviando amostras de voz, lendo determinadas sentenças, para em conjunto criar um sistema de reconhecimento de voz como a Siri e a Alexa, mas em código aberto.
Chamado de Common Voice, o projeto ainda está na fase de captação de amostras de áudio, mas a Mozilla espera ter seu sistema disponível até o fim deste ano. Para Sean White, vice-presidente de tecnologias emergentes na Mozilla, a ideia é, além de tudo, um posicionamento contra o monopólio de informações pelas grandes empresas. “Atualmente, o poder de controlar o reconhecimento de falas poderia acabar em apenas algumas mãos, e não queremos ver isso”, contou, em entrevista ao Verge. Ele conta ao site que, para conseguir dados, as grandes empresas só precisam filtrar tudo que vem para elas de seus usuários, enquanto outros atores, como a própria Mozilla, precisa de outros métodos. “A questão interessante para nós é: podemos fazer isso de maneira que as pessoas que estão criando os dados também se beneficiem?”
Projetos de código aberto têm pouca chance contra produtos comerciais de gigantes da tecnologia, então o que a Mozilla pretende oferecer de diferente para seus usuários e colaboradores? Personalização.
“Para a gente ser bem-sucedido com data commons, precisa haver uma motivação [para os usuários] além de perceberem um dia que estão entregando seus dados pessoais de graça. Temos que tornar sua experiência melhor por terem participado. Queremos que o sistema funcione melhor para você porque parte dos seus dados está incluída”, diz White.
Uma das formas como essa personalização apareceria, segundo o Verge, seria na transformação de dados de sotaques em melhoria prática no reconhecimento de voz para os indivíduos com sotaque.
Sean White sabe que isso ainda não é suficiente para bater de frente com gigantes do porte de Facebook e Google. Este, por exemplo, conta com seu próprio projeto em que empresas terceirizadas pagam usuários do Reddit para que gravem amostras de suas vozes. White prefere então jogar os holofotes sobre a causa que levam para a frente, a favor dos dados abertos: “É uma atividade verdadeiramente democratizante”.
fique por dentro das novidades giz
Inscreva-se agora para receber em primeira mão todas as notícias sobre tecnologia, ciência e cultura, reviews e comparativos exclusivos de produtos, além de descontos imperdíveis em ofertas exclusivas