A maioria dos vídeos deepfake possuem uma falha gritante
A velocidade em que os vídeos deepfake estão avançando é impressionante e inquietante. Mas pesquisadores descreveram um novo método para detectar um “sinal indicador” de que são vídeos manipulados, que mapeiam o rosto de uma pessoa no corpo de outra. É uma falha que qualquer pessoa poderia perceber: os personagens não piscam. • Os vídeos […]
A velocidade em que os vídeos deepfake estão avançando é impressionante e inquietante. Mas pesquisadores descreveram um novo método para detectar um “sinal indicador” de que são vídeos manipulados, que mapeiam o rosto de uma pessoa no corpo de outra. É uma falha que qualquer pessoa poderia perceber: os personagens não piscam.
Pesquisadores da Universidade de Albany, do departamento de ciências da computação, publicaram recentemente um artigo que detalha como eles combinaram duas redes neurais para expor de forma mais efetiva esses vídeos com rostos sintetizados, que geralmente ignoram “atividades espontâneas e involuntárias como a respiração, pulso e movimento dos olhos”.
Os pesquisadores apontam que a taxa média para os humanos é de 17 piscadas por minuto, que aumenta para 26 piscadas por minuto quando estamos falando e diminui para 4,5 piscadas quando estamos lendo. Os pesquisadores disseram que essas distinções são úteis “uma vez que muitos políticos provavelmente leem enquanto discursam e são filmados”. Então quando um personagem de um vídeo não pisca nunca, é um indicativo fácil de que a cena não é real.
Ilustração: Universidade de Albany, SUNY
Existe uma razão pela qual as personagens de vídeos deepfake não piscam: a maioria dos conjuntos de dados utilizados para treinamento de redes neurais não inclui fotos de olhos fechados, pois geralmente as fotos publicadas na internet mostram pessoas com os olhos abertos. Isso é importante, pois é preciso coletar muitas fotos de um indivíduo para criar um deepfake. E a criação é feita a partir de uma ferramenta de captura de fotos que tem código aberto e captura imagens disponíveis na internet.
Estudos anteriores já tinham apontado essa característica como uma maneira de se detectar deepfakes, mas os pesquisadores da Universidade de Albany afirmam que seu sistema é mais preciso do que os métodos de detecção sugeridos anteriormente. Os primeiros estudos utilizaram uma proporção do olho (EAR, na sigla em inglês), ou uma rede neural convolutiva de aprendizagem profunda (CNN) com uma rede neural recursiva (RNN), método que considera estados oculares anteriores, além de quadros individuais do vídeo.
Ao contrário de um modelo apenas convolutivo, os pesquisadores afirmam que o seu método com rede convolutiva recorrente de longo prazo (LRCN) pode “efetivamente prever o estado ocular, de form que seja mais suave e precisa”. De acordo com o artigo, esse método tem precisão de 0.99, contra os 0.98 do CNN e 0.79 do EAR.
Pelo menos, as descobertas dos pesquisadores indicam que os avanços no aprendizado de máquina que possibilitaram a criação desses vídeos falsos ultrarrealistas também pode ajudar a expô-los. Mas os deepfakes estão melhorando a um passo alarmante. Por exemplo, um novo sistema chamado Deep Video Portraits permite que um ator manipule o vídeo retrato de outra pessoa, e permite incluir vários sinais fisiológicos, incluindo olhar fixamente e piscar.
É reconfortante saber que especialistas estão procurando maneiras detectar vídeos deepfake, especialmente porque pessoas mal-intencionadas continuarão abusando da tecnologia para ofender mulheres e, potencialmente, promover a disseminação de notícias falsas.
Mas ainda não se sabe se esses métodos de detecção superarão o avanço rápido da tecnologia de deepfake. E nem sabemos se o público irá parar para analisar de um vídeo é real ou não.
“Na minha opinião pessoal, o mais importante é que o público deve estar ciente das capacidades da tecnologia de geração e edição de vídeo”, escreveu Michael Zollhöfer, professor assistente da Universidade de Stanford que ajudou a desenvolver Deep Video Portraits, em uma publicação no blog. “Isso permitirá que eles pensem mais criticamente sobre o conteúdo de vídeo que consomem todos os dias, especialmente se não houver prova da origem daquilo”.
fique por dentro das novidades giz
Inscreva-se agora para receber em primeira mão todas as notícias sobre tecnologia, ciência e cultura, reviews e comparativos exclusivos de produtos, além de descontos imperdíveis em ofertas exclusivas


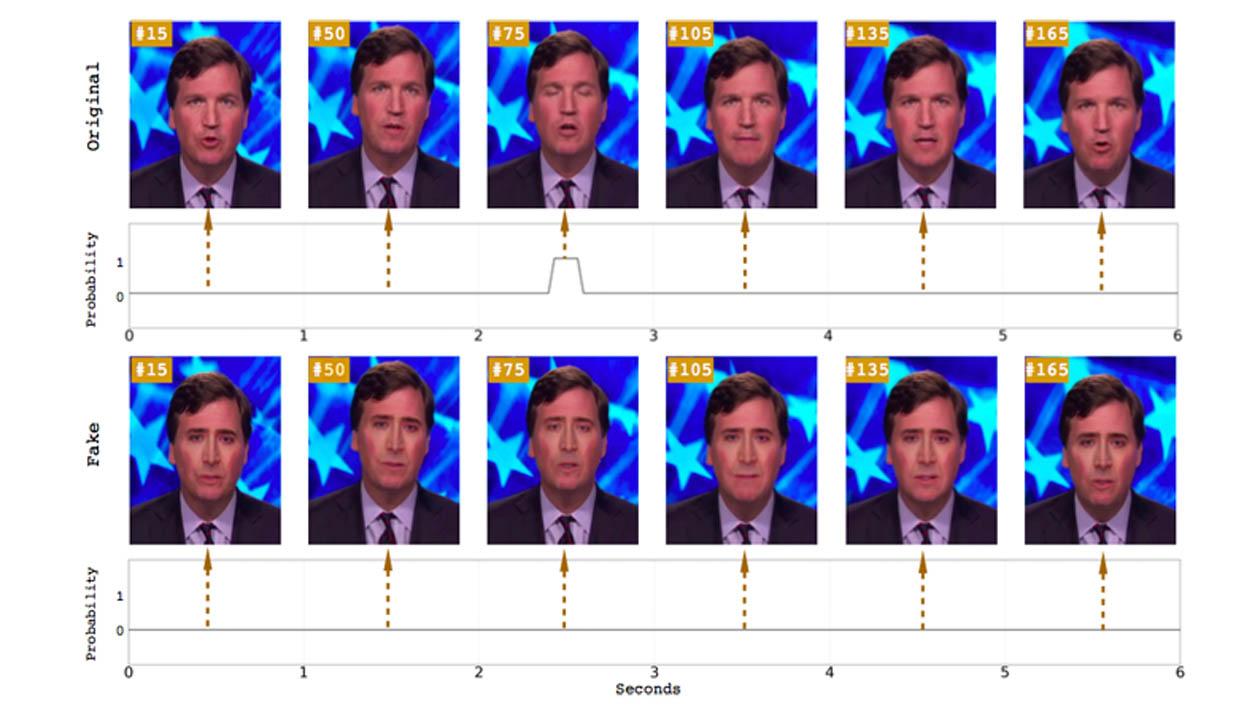

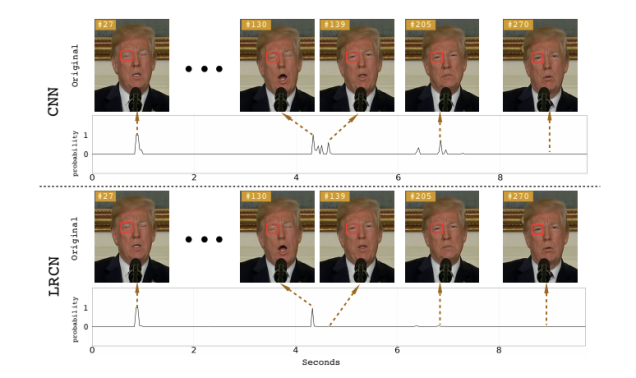 Ilustração: Universidade de Albany, SUNY
Ilustração: Universidade de Albany, SUNY