Já vimos computadores criarem imagens de pessoas que não existem. Mas, e se agora eles conseguirem criar o mapeamento genético completo de alguém que nunca nasceu? Isso pode ser muito útil para proteger a privacidade alheia.
Uma equipe de geneticistas e cientistas da computação tem usado redes neurais para construir novos segmentos de genomas humanos, de acordo com um artigo publicado na revista PLOS Genetics. Seu trabalho pode ajudar a contornar as questões de privacidade inerentes ao trabalho com o DNA de pessoas reais.
Imagine um livro que pode ser continuamente reorganizado em uma história nova e perfeitamente legível, nunca revelando o texto original. Os genomas fabricados oferecem essa possibilidade para pesquisas futuras, possivelmente sem a preocupação de comprometer o código genético de qualquer indivíduo.
“Muitos biobancos, incluindo o Estonian Biobank, exigem procedimentos de aplicação e autorizações éticas para se ter acesso. Essas etapas são cruciais porque os dados genômicos são dados confidenciais e são importantes para manter a privacidade dos doadores. Por outro lado, isso cria uma barreira científica”, disse Burak Yelmen, geneticista da Universidade de Tartu, na Estônia, e principal autor do novo artigo, por e-mail. “Os genomas artificiais podem desempenhar um papel importante no futuro como substitutos de alta qualidade de bancos de dados de genomas reais, tornando-os facilmente acessíveis a pesquisadores de todo o mundo.”
Os dados genéticos oferecem o que talvez seja o maior campo minado ético na privacidade médica, devido ao poder que os genes têm em nos definir. A equipe de pesquisa usou pedaços de informação genética acessível para treinar suas redes, que foram capazes de desenvolver de forma independente pedaços de dados imaginários de genoma que eram quase indistinguíveis da informação genética real.
Haviam alguns indicadores que permitiam diferenciar de um genoma real, Yelmen disse, incluindo a forma que os pedaços de DNA artificiais foram montados. Diferentes pedaços de informação genética foram codificados por cores, ou “pintados”, para ver suas localizações no produto final, e a equipe descobriu que mais pedaços curtos de DNA artificial estavam sendo produzidos do que seria esperado com base em amostras reais do genoma humano.
A equipe não foi capaz de gerar genomas artificiais inteiros devido a limitações computacionais e algorítmicas, mas eles sugeriram “costurar” vários pedaços juntos para obter a ideia genômica completa de um indivíduo inventado.
“O treinamento do modelo é o gargalo aqui. Uma vez que o modelo é treinado, você pode gerar quantos genomas artificiais quiser em segundos”, disse Yelmen. “O treinamento de um fragmento de genoma de 10.000 posições pode variar drasticamente, dependendo de vários fatores.” Com tantas posições – referindo-se às localizações dos pares de bases de um nucleotídeo que ocorrerão em qualquer lugar do código genético – Yelman disse que os modelos às vezes podem ter dificuldade em gerar resultados precisos de forma aleatória.
Um cromossomo (material genético) sobreposto ao código binário. Imagem: Burak Yelmen
O deep learning envolvido na pesquisa utilizou duas abordagens diferentes. Um envolveu redes adversárias geradoras, que usam duas redes neurais em seu processo; o primeiro (o “gerador”) criou instâncias possíveis ou conjuntos de dados sobre os quais o modelo pode aprender. Nesse caso, os conjuntos de dados eram linhas de códigos genéticos gerados aleatoriamente. A outra rede era o “discriminador”, que avaliava a validade da primeira.
Esse resultado foi alimentado de volta para o gerador para tentativas mais precisas. A outra abordagem era uma máquina de Boltzmann restrita, que é uma rede neural de duas camadas que aprende estruturas ao longo do tempo, ajudando a produzir melhores resultados no futuro. No geral, as redes adversárias geradoras são o método preferido para o aprendizado profundo.
A rede adversária geradora da equipe levou alguns dias para treinar inteiramente usando uma unidade de processamento gráfico, acrescentou Yelmen. GPUs são processadores pesados usados para uma variedade de tarefas, desde renderização 3D detalhada até aprendizado profundo.
“Esses genomas que emergem do ruído aleatório imitam as complexidades que podemos observar em populações humanas reais”, disse o coautor Luca Pagani, geneticista também da Universidade de Tartu, em um comunicado do Conselho de Pesquisa da Estônia. “Para a maioria das propriedades, eles não são distinguíveis de outros genomas do biobanco que usamos para treinar nosso algoritmo, exceto por um detalhe: eles não pertencem a nenhum doador de gene.”
fique por dentro das novidades giz
Inscreva-se agora para receber em primeira mão todas as notícias sobre tecnologia, ciência e cultura, reviews e comparativos exclusivos de produtos, além de descontos imperdíveis em ofertas exclusivas


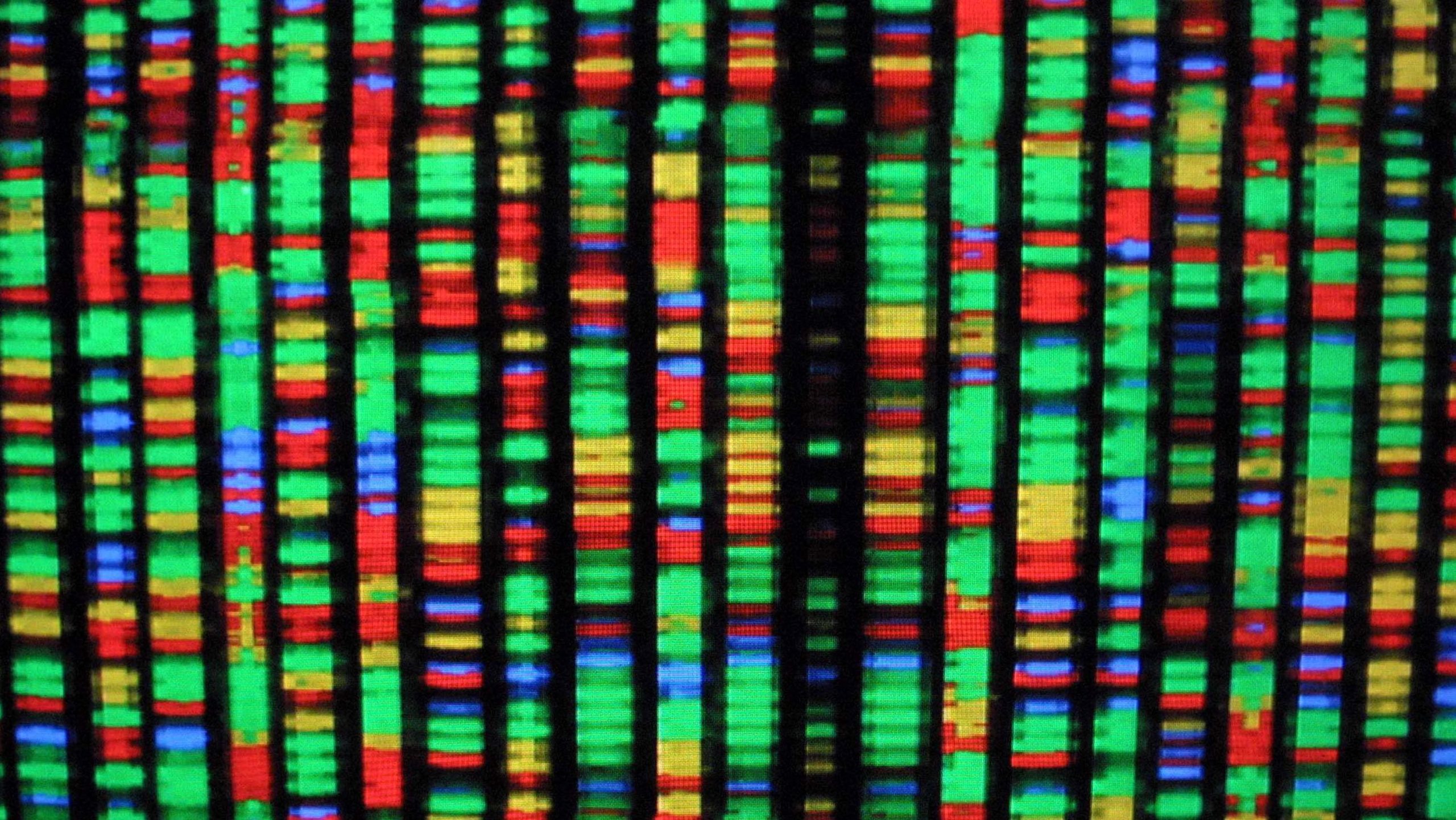

 Um cromossomo (material genético) sobreposto ao código binário. Imagem: Burak Yelmen
Um cromossomo (material genético) sobreposto ao código binário. Imagem: Burak Yelmen







